
FPGA 协处理的进展
FPGA的架构使得许多算法得以实现,较之采用四核CPU或通用图形处理器(GPGPU),这些算法的持续性能更接近器件的峰值性能。随着对芯片、算法和库基础的集中改进,FPGA加速器的基准测试结果不断提高。就算当前最大的FPGA所消耗的功率也不到30W,因此它们可应用于多种场合。在目前出现的几大行业动态的共同作用下,FPGA实现的算法加速更加令人瞩目。这些行业动态包括:
● 当前FPGA的容量已足够容纳更大的算法。现在已经有可能将期权定价算法或1M点快速傅里叶变换放入FPGA。将算法从CPU中加载到FPGA的延迟时间小于算法加速所节省的时间。
● 单核CPU在功耗和冷却问题上受到了限制。采用多核CPU的尝试正在顺利进行,但现有为单核编写的软件必须进行重写,用以支持合理的性能扩展。
● FPGA协处理的主动式支持。在某些情况下,这些CPU接口(AMD公司的Torrenza Initiative与Intel公司面向FPGA厂商的注册FSB与QPI)支持8 GB/s的速率,写入等待时间低于140ns。
较之双核、四核CPU或GPGPU,FPGA基准测试结果显示了采用插槽式加速器的优异的蒙特卡洛浮点结果(见表1)。

就结果而言,运行频率为150~250 MHz之间的FPGA是如何做到优于运行频率为2~3 GHz的四核CPU或运行频率为1.35 GHz的128核GPU的呢?正如蒙特卡洛布莱克-斯科尔算法所示,FPGA架构具有独特的性能,这是产生这一优异结果的原因之一。
FPGA架构特征
灵活的FPGA可根据需要进行编程和重新编程。一个典型的FPGA包括一个逻辑块阵列、内存块和DSP块,它们周边环绕着可由软件进行配置的可编程式互连结构(如图1所示)。该架构确保下列特征的实现。
● 功能并行:功能的多次重复
● 数据并行:处理数据阵列或数据矩阵
● 流水化的自定义指令:每个时钟周期输出流数据的一个结果
● 超大的主缓冲带宽与规模:GPGPU的3~10倍
● 灵活的数据通路布线:巨型交叉连通在一个时钟周期内完成数据传输
● 功能和数据流的串联:均在一个时钟周期内完成
● 定制片外I/O:所需的协议、带宽和延迟
● 可扩展的路径图:更大的阵列具有充足的空间支持供电与冷却
显然,FPGA在并行化与流水化方面存在相当大的优势,同时与GPGPU相比,FPGA在主缓存与带宽方面也存在优势。在FPGA中,逻辑资源周围是存储器块。XDI模块具有一块带宽为3.8TB/s的3.3MB主缓存,这是nVidia 8800 GTX型GPGPU上主缓存(支持流处理器)的5~10倍。
FPGA的优势还在于,可以利用裕量连接带宽来灵活构建直达各逻辑块的数据通道和存储器访问通路。图1所示的可编程互连结构提供了大量的布线带宽。模块与电路板可根据FPGA输出带宽、存储器大小及延迟的需要进行设计,I/O端口可由用户自定义。
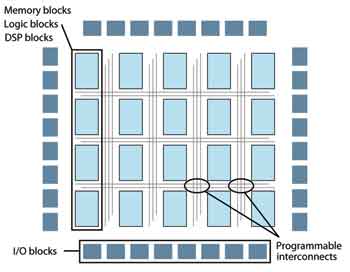
图1 FPGA的架构
最后,FPGA架构还拥有一个优势,它可扩展为更大型的逻辑块、存储器块与DSP块的阵列。逻辑与主缓存的大小是一起扩展的。现有最大的FPGA峰值功耗为30W,其FPGA架构有很多空间,可以在不超过现有数据中心功率和冷却限制的前提下,扩展为新的处理构型。
尽管FPGA架构具有许多出众的性能,一些性能必须共同发挥作用,才能提供优于CPU协处理的解决方案。
芯片与算法基础
大部分双精度浮点算法的加法与乘法操作比例大约为1:1。在FPGA中,加法运算使用逻辑资源,乘法运算使用DSP块,因此FPGA的逻辑资源与DSP块的比例必须均衡。FPGA的另一个特点是其可编程功率技术,该技术可针对所有逻辑块、DSP块与存储器块进行编程,根据设计的时序要求将其设定为高功耗或低功耗模式。
浮点运算核已经改进,可运行于更高的时钟速率,使用更少的DSP块和更少的逻辑资源。采用浮点编译器可减少不同浮点运算核之间用于连接64位数据通路的逻辑资源。
在一次浮点运算结束时,合并对浮点运算进行规格化处理(定点格式转换至浮点格式)的步骤,可以显著减少对后续浮点运算输入的去规格化处理(浮点格式转换为定点格式)。浮点运算的数学表达式的整个数据通路可熔接在一起,这会最多减少40%的逻辑资源并使时钟速率略有提高。
浮点运算的正确组合十分重要。如果算法有许多超越运算(求指数、求对数等),FPGA可配置所需要的数目。在GPGPU设计中,会增加一些硬模块实现上述函数,但比例比单精度浮点逻辑少得多。使用算法技巧、抽象硬件细节及针对个别FPGA资源的优化都需要函数库。
基于芯片、算法与库基础,图2的系统级解决方案涉及到了工具链、模块/板级设计、CPU接口以及采用合作公司专门技术的由CPU至基于FPGA的加速器的数据传输。
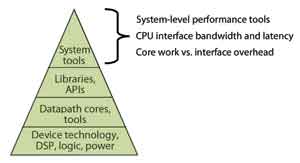
图2 FPGA加速系统级解决方案的基础
使持续性能接近峰值
对于可并行化或流水化的任务,相对于峰值性能而言,FPGA经常能够大大提高持续性能,并可利用各器件资源。以一个蒙特卡洛布莱克-斯科尔斯基准测试程序为例,它可建立一条运行频率为150MHz的等式流水线。
在每个时钟周期,FPGA通过梅森素数旋转核产生的随机数被输入(接入)“定制指令”,每个时钟周期产生一个结果。12条“定制指令”与模块的两片FPGA匹配,利用双精度浮点逻辑输出12×150M=1.8G结果/秒。通过额外倍频,可预期实现性能为上述性能的两倍。
对比不同架构的浮点能力持续性能与峰值性能十分有趣。表2给出了四种可能解决方案的单精度浮点峰值性能。由于布莱克-斯科尔斯公式需要常规加法与乘法函数以外更多的函数(指数、平方根等),布莱克-斯科尔斯结果的总GFLOPS未作统计。
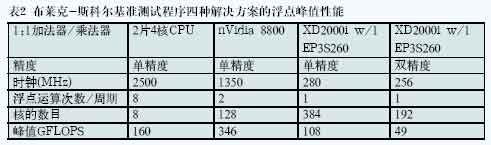
表3给出了布莱克-斯科尔斯结果与峰值GFLOPS的比例,作为比较持续性能与峰值性能的一种相对衡量方法。相比峰值性能,FPGA达到了最佳持续性能。相比另外两种加速器的单精度逻辑,FPGA的双精度逻辑具有最优原始性能以及最优的“性能/瓦”参数。

对许多包含并行性或可流水化的算法而言,由于裕量连接带宽可实现用户自定义的数据通路,这样,逻辑可在一个时钟周期内访问存储器或访问另一个逻辑块的结果,从而使FPGA的持续性能可接近峰值性能。由于固定架构具备预先确定的用以实现不同功能的逻辑块集合,所以可以为FPGA配置支持某种给定算法的最优逻辑函数比例来实现器件资源的最佳利用。